context is everything the model sees
LLMs are stateless. They don't remember you, you remind them who you are with every single message.
In the first post, we established that “Chat” is an illusion: a UI wrapper around a document completion engine.
But if it’s just completing a document, how does it hold a conversation? How does it know I asked about Python three messages ago?
The answer is simple: the model doesn’t remember, it just reacts to the tokens currently in the buffer.
The Amnesiac Author
Imagine a brilliant but exhausted author who suffers from total explicit amnesia. They can write beautifully, but the moment they put their pen down, they forget everything they just wrote. They forget who you are. They forget they are even a writer.
To get this author to write a story for you within a conversational flow, you have to adopt a very specific workflow:
- You walk into the room and hand them a page comprising the story so far.
- They read it, write one single sentence at the bottom, and hand it back to you.
- They immediately forget everything.
- To get the next sentence, you must hand them the entire page again (including the sentence they just wrote) plus your new instruction.
This is exactly how an LLM works. There is no “session” on the server, and there is no hidden “memory” bank where it stores your chat history. The API is a stateless function:
output_token = model(context_window)It takes the tokens you give it, predicts the next piece, and terminates.
The Autoregressive Reality
While we often say context is what you send, in reality, context is everything the model “sees” at the moment of prediction.
This includes:
- The Prompt: The history and instructions you provided.
- The Output-so-far: The tokens the model has already generated in the current response.
- The Hidden Context: Internal reasoning traces or “thinking” tokens.
As the model generates a sentence, it is constantly reading its own previous words to decide the next one. This autoregressive loop means the “author’s” manuscript isn’t just the page you handed them, it is the sum of your input and their own reasoning output.
When we talk about the “context window,” we aren’t talking about the model’s memory. We are talking about the input buffer for the current function call.
Visualizing the Accumulation
Because the model forgets immediately, the “memory” of a conversation is actually just a growing log of text that you (the developer) manage. You aren’t “saving” text to the model, you are “resending” the log.
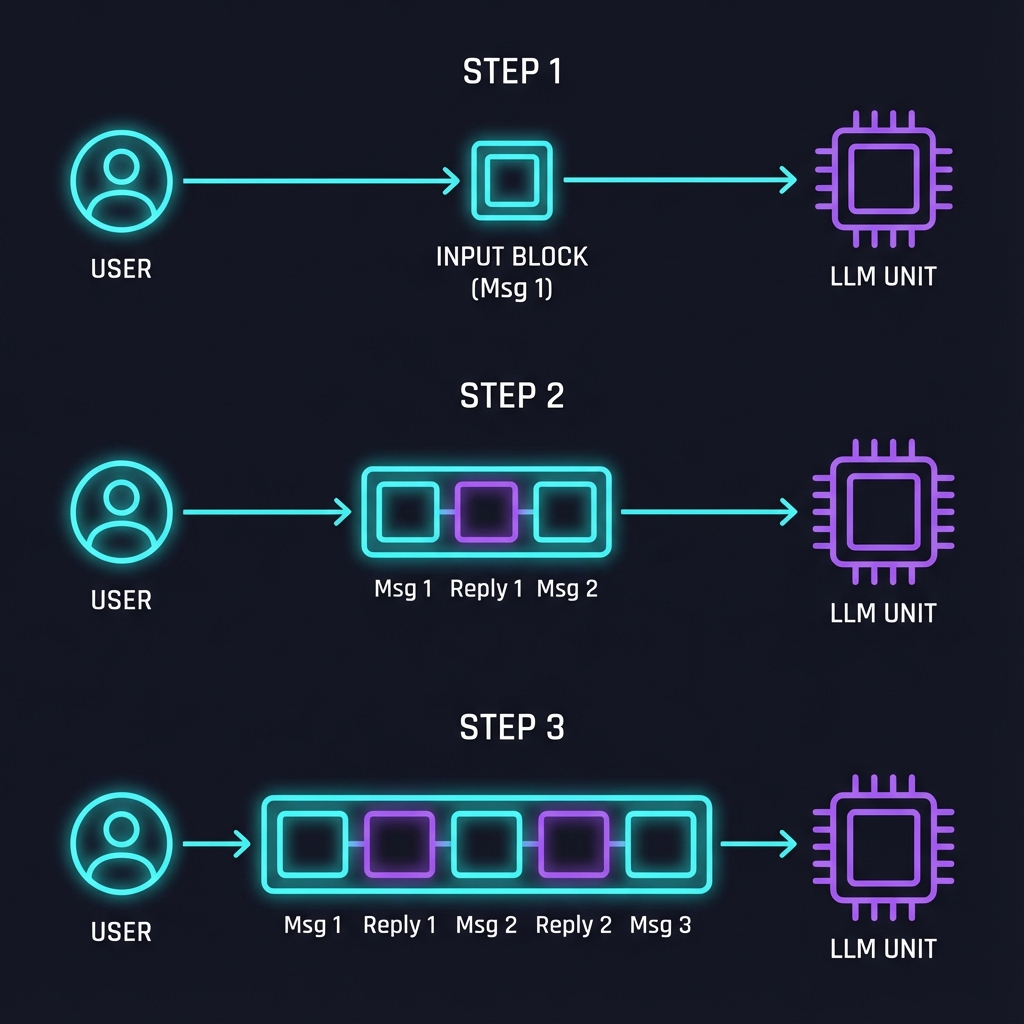
Notice how the input payload (the cyan box) grows linearly with every turn. By Step 3, you are paying to re-process Message 1 and Reply 1 again, just so the model has the context to answer Message 3.
Context != Memory
This distinction fundamentally changes how you architect AI applications.
Memory implies persistence. If I tell a database my name, it remembers it tomorrow.
Context is ephemeral. It exists only for the duration of the generation.
If you want an LLM to “remember” something from yesterday, you have to fetch it from your database (memory) and paste it into the prompt (context) right now. This is the entire basis of RAG (Retrieval Augmented Generation). RAG is simply a mechanism to swap things in and out of the “amnesiac author’s” manuscript because the manuscript has a valid page limit.
The Cost of Amnesia
The “context window” has a hard size limit (e.g., 200k tokens). But long before you hit that limit, you hit the latency/cost barrier.
Since you are re-sending the entire history every time:
- Cost grows quadratically (or linearly if caching is enabled) with conversation length.
-
Latency increases because the model has to “read” (process) existing tokens
before generating the next token.
The Cache Exception
Recently, providers like Anthropic, Google, and OpenAI have introduced context caching. This allows the server to keep the “processed state” (KV cache) of the prefix tokens in memory for a short time.
While this saves compute (generating the keys and values from scratch), the model still has to attend to those cached states. The “Author” doesn’t have to re-read the text word-by-word to build their mental model again (compute KVs), but they still have to think about that information (attention) to write the next line. Every token must still compare itself with every other token.
This is why, even as windows grow to millions of tokens, we still have an attention budget.
Summary
- Stateless: The model is a fresh instance every time.
- Context is Visibility: Context is everything the model “attends” to, including its own current output.
- You are the Database: The client is responsible for maintaining long-term state.
In the next post, we’ll look at the system prompt, the one piece of context that claims to be a “rule” but is really just more text.